


Summary
Analysis is the process of gathering and comparing information about the web and its operation and use in order to improve the web's overall quality and to identify problem areas.
A web analyst checks to make sure the web works:
- Rhetorically: Is the web accomplishing its stated purpose and meeting its objectives for its intended audience, including satisfaction of identified revenue models?
- Technically: Is the web's presentation functionally operational and consistent with its specifications and design as well current HTML practices and syntax?
- Semantically: Is the web's domain information content correct, relevant, and complete? Is the web's user interface usable and effective?
| Analysis Checklist | |
|---|---|
| Point | Evaluate if the web... |
| A | Attempts to reach an audience that has and will use Web access |
| B | Contributes new information (accomplishes goals that haven't already been done) |
| C | Is self-consistent (its purpose matches its objectives and specifications) |
| D | Is correct (the domain information it presents is accurate, up-to-date, and complete) |
| E | Is accessed in a balanced manner, both in terms of its own files and in terms of outside links into it |
| F | Is accomplishing objectives that meet the needs of the users |
An analyst weighs alternatives and gathers information to help with the other processes of web development, including planning, design, implementation, promotion, innovation.
Key Analysis Practices
- Observe representative audience members using your web (usability analysis).
- Evaluate the consistency and verify correctness of the information content of your web.
- Check the technical implementation of the web with validation tools.
- Ask yourself these questions about your web to see if you might be making some of the more common mistakes.
Key Analysis Resources
- https://www.useit.com/
Designing Web Usability: This is Jakob Nielsen's site on Web usability and provides excellent coverage of Web page layout and design techniques. Dr. Nielsen provides links to his numerous papers and essays concerning usability, including his expertise in heuristic evaluation and usability metrics. - https://usableweb.com/
Usable Web: This site provides a large collection of links about human factors, interface design, and usability issues specific to World Wide Web development. The resources are described, and mutiple organizational schemes allow for searchng by date, site, topic, or popularity. Topics covered include news, usability engineering, design, calendar of events, issues, sources, and technology. - The HTML Toolbox
This provides references to a variety of tools to use in implementing a Web site.
Discussion
If you have just planned a web, a big question that should be in your mind is, "Will the web accomplish its purpose?" Even when a web already is deployed and operating, you frequently should investigate whether the web is accomplishing its planned objectives. The web analysis techniques presented in this article are intended to help you check web elements in a planned or operating web. This analysis process covers the technical validation of a web's HTML implementation as well as analysis of the web's planned or existing content and design. This process also touches on usability and style issues. Because of the dynamic information environment in which a web operates, these ongoing efforts to evaluate web quality and usability may be the key to increasing the effectiveness of an organization's Web communication.
The figure shows the key information needs of a web analyst for all the web's six elements: purpose and objective statements, audience and domain information, and specification and presentation. The overall goals of a web analyst are
-
Check to make sure that the web works:
- Rhetorically: Is the web accomplishing its stated purpose for its intended audience?
- Technically: Is the web functionally operational, and is its implementation consistent with current HTML specifications?
- Semantically: Is the web's information content correct, relevant, and complete?
-
Make recommendations to the other web-development processes:
- Advise on new web planning, including administrative and information policy.
- Give input to web designers on user problems or redesign ideas.
- Recommend maintenance to web implementers.
- Give reports to web promoters about user experience with the web.
- Collaborate with web innovators by providing insight for improving the web's content or operation.
The web analyst thus acts as a reviewer, evaluator, and auditor for the web-development process. When practical, therefore, the web analyst should be as independent as possible from the duties of web implementation, design, and planning.
Web Analysis Principles
Based on the characteristics and qualities of the Web, web analysis should pay close attention to evaluating how the web is consistent with the following principles:
- Strive for continuous, global service. Because a characteristic of an operating public web is that it is available worldwide, 24 hours a day, an analysis of its content and operation must take into account a multinational, multicultural audience and its needs for continuous access.
- Verify links for meaning as well as technical operation. As networked hypermedia, a web extends and augments its meaning through internal and external links. External links tightly bind a web within larger contexts of communication, culture, and social practice that extend beyond an organization's outlook. A rhetorical and semantic analysis of links in a web therefore must look at how links contribute to a web's meaning. Technical analysis of links must ensure their operation and availability to the degree possible.
- Ensure porousness. A web that contains more than one page offers multiple entry points for its users. An analysis of the usefulness of a web must examine how each of these multiple pathways offers a user the right amount and level of information to use the web well. A close analysis of a web's design should reveal multiple strategies for addressing porousness.
- Work with dynamism. A web operates in an environment in continual flux in terms of meaning and technologies. Not only are new webs introduced all the time that try to accomplish the same purpose and/or reach the same audience of a given web, but methods for implementing and experiencing webs continually are introduced and upgraded. An analyst needs to keep abreast of the state of the Web's information and technical environment in order to evaluate a web's effective operation.
- Stay competitive as well as cooperative. Because of the Web's dynamic nature, an analyst as well as the web's innovator must work to know the competitive webs that vie for their audience's attention. Opportunities also exist for competitor webs to combine, using the features of linked hypertext, to better serve the audiences.
In summary, a web analyst is concerned with principles for the technical and rhetorical integrity of a web. The goal is to create a web that works with the characteristics and qualities of networked hypermedia to best accomplish the web's purpose for its audience.
Information Analysis
A web analyst can evaluate many of the web's technical and rhetorical aspects by analyzing the web's elements (audience information, purpose and objective statements, domain information, web specification, and web presentation) and performance (information about how users have used or are expected to use the web). This information analysis process also involves gathering information about other competitor webs that may be accomplishing a similar purpose or reaching a similar audience. When performed with the other people involved in web development processes, web information analysis serves as a check of the web's overall quality and effectiveness. Web information analysis seeks to uncover the answers to the following general questions:
- Is the web accomplishing its stated purpose and meeting its planned objectives?
- Is the web operating efficiently?
- Are the intended benefits/outcomes being produced?
Although a definitive answer to these questions might be impossible to obtain at all times, web analysis can serve as a check on the other development processes. This section looks at information analysis checkpoints that can be examined during a web's planning or after it is implemented. This analysis process involves gathering information about a web's elements and comparing it to feedback from users and to server statistics.
The figure at the right shows an overview of information useful in analysis. In the figure, the web's elements are in rectangles, and supporting or derived information is in ovals. Key checkpoints for analysis are shown in small circles, labeled A through F. At each checkpoint, the web analyst compares information about the elements or information derived from the web elements to see whether the web is working or will work effectively.
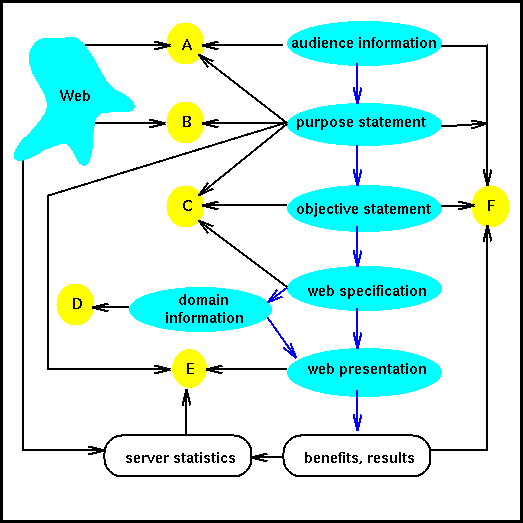
The information about the web elements and derived information varies in completeness depending on how far the developers are into actually implementing the web. A web analyst can obtain information about the web elements from the results of the planning, design, implementation, or development process. If the developers have just started the planning process, web analysts can analyze the checkpoints for which they have information. A web analyst can obtain the derived information through examining web statistics. Ideally, a web analyst will be able to observe representatives from the intended audience as they use the web. If web analysts don't have a working web ready, these audience representatives may give feedback on a mock-up of the web, its purpose statement, or a diagram of its preliminary design.
The key to the analysis process is that it is meant to check the overall integrity of the web. Results from the analysis process are used in other processes to improve the web's performance. If analysis of the web's domain information shows that it is often out of date, for example, the planning process needs to be changed to decrease the time between updating the domain information. The analysis process on the web's elements helps all processes of web weaving work correctly and efficiently. The following sections go through each of the analysis checkpoints shown in the diagram.
Does the Audience Exist on the Web for the Given Purpose? (Checkpoint A)
Before spending too much time in the planning process defining and describing a target audience, web analysts first should check to see whether this audience can use the web at all. Although the interests of all the people who use the WWW are increasingly growing diverse, a routine check of the Web's demographics or contents might tell web analysts something about the size of the audience they want to reach.A number of research organizations study and present information on Internet demographics. Their reports give a fascinating picture of the evolving nature of the online user.
- Pew Internet & American Life Project
-
https://www.pewinternet.org
The Pew Internet & American Life Project researches the impact of the Internet on people, communities, the workplace and civic life. The project's Web site offers a wealth of free and very detailed reports that profile Internet use and trends.Some Pew research has overturned stereotypes. For example, one project found that Internet users are far from antisocial nerds. In fact, they found that Internet users have more extensive social lives than non-users. Another project challenged the notion that everyone will eventually be online. Research found that 57% of people who did not already have Internet access did not plan to get access. In the spring of 2001, a Pew study confirmed again that the gender gap in Internet access has narrowed: of the 104 million American adults with Internet access, 50.6% are women.
- Cyberatlas
-
https://www.cyberatlas.com
Cyberatlas is a directory that links to research involving online retailing trends, finance and advertising news. The "Stats Toolbox" section allows you to easily select the kind of statistics you need, such as demographic usage statistics, online populations, browser statistics, top Web properties and more.The links to the statistics in each case identify the research organization(s) behind the numbers. Fascinating nuggets among these statistics abound. For example, an Arbitron/Edison Media Research study in 2001 found that one-third of Americans with Internet access at home would give up television if forced to choose between television and the Internet.
A September 2000 Nielsen/NetRatings study found that the top three cities in terms of the percentage of households accessing the Internet from home with a personal computer were: San Francisco (66%), Seattle (64%) and San Diego (62%). Milwaukee came in 30th at 46%, right between 29th place Chicago (46%) and 31st place Minneapolis (45%).
- eMarketer
-
https://www.emarketer.com
Using a magazine-style format, eMarketer keeps you up to date on the latest trends in online marketing and demographics with news, feature stories and reference information. While much of the content is free to browse, detailed and specific reports cost money. For example, a 335-page March 2001 eCommerce report costs $795. This is not an atypical price for a detailed and current online demographic study in key business areas.The free content in the eMarketer news sections, however, provides a great service for tracking the shape of online business and marketing. For example, in the news section, a link to an American Demographics (https://www.demographics.com) article characterizes the online population as shifting away from a majority of "geeky white guys" to a far more diverse population, with the highest growth being among the "Walmart crowd"-Americans over 55 years old with working-class incomes and middlebrow tastes.
- Internet Geography Project
-
https://www.zooknic.com
If you are fascinated with the geographical dispersion of the Internet audience, this site is for you. Tackling the complex task of measuring Internet users and domains by geographic region, this site is a project of Matthew Zook of the University of California, Berkeley Department of City and Regional Planning. Included in the analysis are some fascinating maps showing the dispersion of the 377 million Internet users worldwide as of September 2000.Zook also tracks the number of Internet domains by state. A January 2001 count of Internet domain names ending in "dot com" showed California and New York on top with 1,843,900 and 721,725 domain names respectively. Wisconsin came in at number 25 with 105,600 domain names. In terms of the growth of total domain names registered from July 1998 to January 2001, Wisconsin came in 49th, ahead only of Kansas.
- Nua Internet Surveys
-
https://www.nua.ie/surveys
Based in Ireland, Nua is a Web publishing software company that has gained widespread attention for its Internet Surveys Web site. Its surveys and news links give a comprehensive overview of many measures of Internet audience size and activity. Nua's site also organizes survey results by industry sector-ranging from advertising and the auto industry to telecommunications and travel. Weekly editorials, bi-monthly reports and year in review sections round out the site. - Stanford Institute for the Quantitative Study of Society
-
https://www.stanford.edu/group/siqss/
While not focused entirely on the Internet, this Stanford research group has conducted some notable studies about the social impact of Internet use. A major study of the social consequences of the Internet looked at a representative sample of 4,113 adults in 2,689 American households. A key finding of this study, according to Institute director Professor Norman Nie, was that "the more hours people use the Internet, the less time they spend in contact with real human beings."The Stanford study also found that 25% of respondents work at home on the Internet without a corresponding reduction their office work. Stanford also found shifts in media use with 60% of regular Internet users who have reduced their television viewing time to instead spend time online.
- eLab
-
https://elab.vanderbilt.edu
If you are doing any marketing online, this site is a must-visit. Put together by professors at Vanderbilt University, this site provides a deep view of research and theory about analyzing how people react to online marketing. This site has become well-known for its work in de-bunking poor research (e.g., "cyberporn" from Carnegie Mellon, and Neilsen's ratings of Internet usage). Strength: detailed research and discussion; insightful analysis and de-bunking. Weakness: discussion and materials can tend toward academic-speak.
Without demographic statistics, the other way to see whether the audience is on the Web (or the Net) is to check for subject-oriented information resources and forums that are of interest to the audience. If the target audience consists of botanists, for example, what on-line information already exists that shows botanists as active on the Web and the Net? A web analyst can find out by:
- Searching subject-oriented trees for resource collections related to botany
- Locating institutions-academic, commercial, or research-that are involved with botany
- Checking Usenet newsgroups and FAQ archives to see what botanists are active on the Net
- Checking to see whether there is an on-line mailing list devoted to botany
- Checking to see whether professional societies or publications in the field of botany offer an on-line forum or information service
Web analysts can interpret the results of the check of demographic statistics or Net resources related to the subject in two ways. First, if they find nothing, it might mean that the audience has made no forays into the Net-no newsgroups, no mailing lists, and no on-line collections of resources at major institutions. Based on this, web analysts could decide that the web would fill a great need for this audience. In contrast, they might conclude that this particular audience is not interested in on-line communication at all.
To decide which of these two alternatives is more accurate, web analysts should consult representative audience members. Analysts can check with people in the field and ask them, "What if you had an on-line system for information and communication?" Because on-line electronic mail discussion lists have been around longer than many network communications forums, an on-line mailing list that the target audience uses can be a good source of information about that audience's interests. Another aspect of this analysis of audience information is to make sure that the purpose for the web is one that meets the audience's patterns of communication, or at least the patterns in which the audience is willing to engage.
Web analysts might find that certain audiences are not willing to have a publicly available forum for discussion and information because of the nature of their subject matter, for example. Computer security systems administrators might not want to make detailed knowledge of their security techniques or discussions publicly available on a web server.
Certainly, private businesses or people involved in proprietary information might not want to support a web server to share everything they know. These same people might be interested in sharing information for other purposes, however. Computer security administrators might want to support a site that gives users advice about how to increase data security on computer systems. Thus, the web's purpose statement must match the audience's (or information provider's) preferred restrictions on the information. Current technology can support password protection or restricted access to Web information so that specific needs for access can be met.
Through a check of the audience, purpose, and communication patterns for that audience, web analysts quickly can detect logical problems that might make a web's success impossible. If the web's purpose is to teach new users about the Web, for example, web analysts might have a problem if the audience definition includes only new users. How can new users access the web in the first place? In this case, the audience should be redefined to include web trainers as well as the new users they are helping. This more accurate audience statement reflects the dual purpose of such a training web: getting the attention, approval, understanding, and cooperation of trainers as well as meeting the needs of the new users. If web analysts have an accurate audience statement, all the other processes in web weaving, such as design and development, can work more efficiently because they take the right audience into account.
Is the Purpose Already Accomplished Elsewhere on the Web? (Checkpoint B)
Just as web analysts don't want to reach an audience that doesn't exist or target an audience for a purpose they don't want to achieve, they also don't want to duplicate what is being done successfully by another web. Checkpoint B is the "web literature search" part of the analysis: "Is some other web doing the same thing as what the web analyst wants to do? What webs out there are doing close to the same thing?" These questions should be asked at the start of web development as well as continuously during the web's use. New webs and information are developed all the time, and someone else might develop a web to accomplish the same purpose for the same audience.
To find out whether someone has built a web for a specific audience and purpose, use the subject and keyword-oriented searching methods. Web analysts also might try surfing for a web like this or for information related to the audience and purpose. During this process, save these links; if they are relevant to the audience and purpose, they can become part of the domain information on which the web's developers and users can draw.
The other benefit of this web literature search is that web analysts can find webs that might be accomplishing the same purpose for a different audience. These webs might give web analysts ideas about the kinds of information they can provide for the audience. Also, they might find webs that reach the same audience but for a different purpose. These webs can give useful background or related information that web analysts can include as links in the web. If they find a web that reaches the same audience for the same purpose, they can consider collaborating with the developers to further improve the information.
Do the Purpose, Objective, and Specification Work Together? (Checkpoint C)
One of the most important elements for the integrity of the web is the purpose, objective, and specification triad. These three elements spell out why the web exists and what it offers. The purpose statement serves as the major piece of information the potential audience will read to determine whether they should use the web. If the purpose statement is inaccurate, the audience might not use the web when they could have benefited from it, or they might try to use the web for a goal they won't be able to accomplish.The check of the purpose-objective-specification triad is to make sure that something wasn't lost in the translation from the purpose (an overall statement of why the web exists) to the objective statement (a more specific statement of what the web will do) to the web specification (a detailed enumeration of the information on the web and constraints on its presentation).
During the development of the specifications, the analyst might find that a piece of information was added that has no relation to the stated purpose. Or some aspects of the stated purpose might not be reflected in the specification at all.
One way to do this check is to make a diagram that traces the links from the purpose statement to the objective statement to the specifications-both top-down and bottom-up. Each objective gives rise to specifications for the web. From the bottom up, every specification should be traced to an objective, and each objective should be traced to some aspect of the purpose. Every URL and component of the specification should be traced back to an objective, and each objective should be traced back to the purpose statement. If there is a mismatch, more planning must be done to restate the purpose, objectives, or specification so that they all match.
Is the Domain Information Accurate? (Checkpoint D)
The quality of the domain information affects the users' perceptions of the web's overall quality. Inaccurate or incomplete information hinders web developers and leads to dissatisfaction by the web's users. The domain information must be checked to make sure that it is accurate, updated, and complete. Periodic checks can be made according to the nature of the domain.
There are two kinds of domain information: the information that the web developers need to understand enough to plan, analyze, design, implement, and develop the web; and the domain information that the web provides to its users. Remember also that domain information of the first type does not need to be located on the Net at all; it might include textbooks or courses the web developers use as a means of getting up to speed in the area of knowledge the web covers. This kind of domain information also can serve as reference information throughout the course of web weaving.
Verifying the accuracy, currency, and completeness of the domain information is a difficult task because the web analyst must have adequate knowledge of the subject matter to make a judgment about the veracity of all domain information. Although the verification of off-Net resources, such as books and courses, can be evaluated according to the same judgment the analyst uses for similar off-line materials, the Net information included in the first type of domain information and all the second type of domain information can be checked through a process of Net access and retrieval.
The process for checking Net-accessible domain information follows. For domain information provided to developers but not users of the web (the first type of domain information, which is Net-accessible), check the web page provided to developers in the same manner as described in the following paragraphs.
Verify the freshness of links. If the web is operational, use the links provided in the web itself to ensure that the links are not stale and that the resource has not moved. (The section "Implementation Analysis," discusses checking links in more detail.)
Check the accuracy of the information. If the web purports to respond with the correct solution to a problem given a set of inputs (for example, a physics problem answer through a forms interface), have a set of conditions that lead to a known result. Test the web to verify that it yields the same answer, and vary the test cases the web analyst uses.
Use reliable and authoritative sources. Use these sources, when available, to verify the new information added in the web since the last analysis. If necessary, contact the developer of that information and discuss his or her opinions of the information's accuracy.
In the case of databases, make sure that they are as current as they possibly can be. This is crucial, for example, if the web serves out time-dependent data, such as earthquake reports. If the web analyst is not getting a direct feed from an information provider who supplies the most current information, check to make sure that the most current reports or data have been downloaded to the database that the web analyst uses in the web.
Compare all specifications to items in the database. Are there any specifications calling for information that currently is missing?
Check locations on the Net. Use the methods of navigation described in Part III, "Web Implementation and Tools," to locate more current or reliable domain information.
Check locations on the Net to find other domain information that might be helpful as background to developers. Also look for information that could be part of the objective statement of the web.
Is the information at the right level of detail? Are the web weavers getting the right level of information for their work? Are the web's users given the right amount of information, or is there an information overkill or an oversimplicity in what is offered?
Is any of the information not appropriate for the users or the Web community at large? Is any of the information unethical, illegal, obscene, or otherwise inappropriate? Check links to outside information to verify that users will not encounter inappropriate material. Clearly, for outside sources of information, web analysts will be limited in the ability to control inappropriate information. Include this check in the analysis process to make decisions about what outside links the web analyst wants to use.
Is the Web Presentation Yielding Results Consistent with the Web's Design and Purpose? (Checkpoint E)
The goal of this checkpoint is to determine whether the web, based on server statistics or feedback from users, is being accessed consistently with how the web analyst wants it to be used. One part of checking this consistency is to find out whether the web server's access statistics show any unusual patterns. A web server administrator should be able to provide the web analyst with a listing of the web's files and how many times they have been accessed over a given period of time. Although this file-access count is a simple measure of web usage, using it might reveal some interesting access patterns. A check of the web's files, for example, might show the following access pattern over the past 30 days:
File Number of Accesses
top.html 10
about.html 9
overview.html 5
comic.html 5800
resources.html 200
people.html 20
newsletter.html 8
This shows a fairly uneven distribution of accesses in which a single file is accessed many times (the 5800 shown for comic.html). Compared to the small number of accesses to a "front door" (top.html) of the web, this pattern shows a problem unless this imbalance was intended. Also, the statistics show that the newsletter isn't being read very much, whereas the resources are being accessed quite a bit. In order to interpret the web's access statistics, the analyst should ask the following questions:
Does the overall pattern of access reflect the purpose of the web?
Does the pattern of access indicate a balanced presentation, or are some pages getting disproportionate access? Does this indicate design problems?
If the web's "front door" page isn't getting very many accesses, this could indicate problems with the publicity about the web.
Another aspect of verifying the web's consistency of design and purpose is to see that it is listed and used in appropriate subject indexes related to the subject of the web. Does the web analyst find links to the web on home pages of people working in the field? Is the general reputation of the web good? A web analyst can find answers to these questions by doing web spider searches to find what pages on the web reference the pages. Check major subject trees to see whether the web is represented in the appropriate categories. Much of this analysis of the web's reputation is useful in the development and process.
Do the Audience Needs, Objectives, and Results of Web Use Correspond to Each Other? (Checkpoint F)
It is very important that web analysts determine whether the audience's needs are being met by the web. To do this, they must compare the audience information (the audience's needs and interests) with the objective statement and the intended and actual benefits and results from the web. Information about the actual benefits and results of the web's use is the most difficult to come by. Web analysts can use several methods, however, to get a view of the effects of the web:
Ask users. Design and distribute a survey. This could be done using the forms feature of HTML if web analysts are willing to use features not found on all web browsers. They could distribute the survey by e-mail to a random sample of users (if such a sample can be constructed from a listing of registered users or derived from web-access logs). Include in this survey questions about user satisfaction. Are the users satisfied that the web meets their needs? What else would the users like to see on the web? How much do users feel they need each of the features the web offers?
Survey the field. Is the web used as a standard reference resource in the field of study? This is similar to the analysis performed at checkpoint E, but instead of just focusing on the occurrence of links in indexes and other web pages, web analysts need to analyze the web's reputation in the field of study or business as a whole. Do practitioners generally recommend the web as a good source of information?
Are the web analysts accomplishing the purpose? Are outcomes occurring that the web analysts specifically stated in the purpose? If one phrase of the purpose is to "foster research in the field," for example, is there any evidence to support this? Is there research published that was sparked by the interactions the web fostered? If the web analysts have a commercial web, how many sales can they say the web generated? Determine some measure of the purpose's success and apply it during the analysis process.
Another way to look at checkpoint F is to ask the broader question, "Is the web doing some good?" Even though the web might be under development and its objectives still have not truly been met, is there at least some redeeming value of the web? What benefits is it offering to the specific audience or even to the general public? A commercial site that also provides some valuable domain information, for example, is performing a public service by providing education about that topic.
Another approach is to conduct research using theory and methods from the fields, such as Computer-Mediated Communication, Computer-Supported Cooperative Work, Human-Computer Interaction, or other disciplines that can shed light on the dynamics of networked communication. These fields might yield theories the web analysts can use to form testable hypotheses about how the web is working to meet users' needs, to foster communication, or to effectively convey information.
The key to checkpoint F is to make sure that the other checkpoints-A through E-are working together to produce the desired results. A web analyst will notice that checkpoints A through E each touch on groups of the web's elements. Only checkpoint F spans the big-picture questions: Are the people who use the web (audience information) getting what they need (purpose, objective, benefits/results) from it?
Design and Performance Analysis
Not only should the information in a web be analyzed for its rhetorical and technical integrity, but the overall design of a web also should be evaluated for how well it works as a user interface and for its intended purpose and audience.
Performance
One of the most important impressions a web gives to users is how much it costs them to retrieve the information in it. One aspect of user cost related to the technical composition of a web is retrieval time. Many inline images and extremely large pages can cause long retrieval times. Performance for users varies widely, based on the browsers they use, the type of Internet connections they have, and the amount of traffic on the network and the Web server.
Analysis can be done, however, in general terms, to get some ideas of retrieval times. Here is a possible (not necessarily definitive) checklist for web-performance analysis:
- Retrieval time. The analyst can retrieve the pages of the web using a browser and time how long it takes to download them. If the analyst retrieves the web pages from a local server (that is, a server on the same local network as the analyst's browser), these retrieval times, of course, will be less than what a typical user would encounter. Therefore, it might help if an analyst has an account or a browser available that is typical of most users-perhaps an outside account on a commercial service or at a remote site. This remote browser account then can be used to time the retrieval of the web pages. The analyst can report the retrieval times to the web designers. In many cases, it might be difficult to determine exactly what is "too long" for retrieval times. An analyst can look for pages that are very long and pages that contain a great deal of inline images, however, and evaluate whether the download costs of these pages are appropriate for the web's audience and purpose.
- Readability. This is a simple test to see whether the user can read the text on the pages of the web. With the advent of background images, developers often create textured and colored backgrounds that make reading unpleasant and sometimes nearly impossible.
- Rendering. The analyst should test the web in various browsers just to make sure that the information is available to users. This rendering check should be done to the level specified during the planning stages. If essential information is available in text, the analyst can use text-only browsers to make sure that information (including information in image ALT fields) is set to guide users without graphics.
-
Aesthetics.
Aesthetics, which are a subjective impression of the pleasing quality of a web, are difficult to test. Some guidelines, however, can help an analyst evaluate the aesthetics of a web:
Does the web exhibit a coherent, balanced design that helps the user focus on its content? One design problem associated with a lack of aesthetic focus is the clown pants design method: The web consists of pages containing patches of information haphazardly organized. A related (poor) design technique is the K00L page design method; The web designer apparently attempts to use every HTML extension possible-including blinking text, centered text, multiple font sizes, and blaring, gaudy colors. An analyst should try to identify page designs that fall outside the purpose of the web or the audience's needs.
Do the web's pages exhibit repeated patterns and cues for consistency, with variation in these patterns for expressiveness? Repetition with expressive variation is a design principle used in many areas, such as graphic design, architecture, painting, textile design, and poetry. Which graphic elements are repeated on many pages for consistency? What content is varied to convey informational or expressive content?
How is color used? Color can be used effectively to code information or to focus user attention. Randomly used color can confuse the user, and some users have impaired perception of color. Complementary colors used on top of each other often give a jarring, shimmering effect.
Usability
Analysts can test a web for usability in a variety of ways. The quick ways of usability testing can give inexpensive, rough ideas of how well the web is working. More elaborate methods of usability testing can involve controlled experiments that might be prohibitively expensive. Here's a checklist to analyze the usability of a web, starting with the quick, simple, and inexpensive methods:
Perform a simple web walkthrough. With the web's purpose and audience definition in mind, analysts can perform a simple check of the pages, looking to see whether the major objectives are met.
Check sample user tasks. Based on the purpose statement and audience information for the web, analysts should be able to devise a set of tasks that the user is expected to accomplish. They then can use the web to accomplish these tasks, noting any problems along the way.
Test tasks on representative users. Based on the list defined in the preceding check, analysts can find several representative users and observe them as they complete the tasks. They might ask the users to say aloud what they are thinking when trying accomplish the tasks. They might record this narrative, gather recordings from several audience members, and then analyze the transcripts. This might help not only in web analysis, but also in redesign ideas.
Perform field testing with actual users. This method attempts to get a true sense of how the web actually is used. Analysts need to be able to select random users of the web and observe them in the settings in which they use the web. The users of a web might not be located in a single geographic area, so, obviously, this type of testing can be very difficult and expensive. Alternatively, extensive interviews of actual users or focus groups of users might give better insight into how the web is being used.
Semantics
Semantics refers to the meaning conveyed by the pages of the web. Through many of the information-analysis steps outlined previously, the analyst would have addressed many aspects of how the web conveys meaning. But a separate check of the web, focusing only on semantics, might reveal problems not detected in other ways:
- Check for false navigational cues. Some designers put arrows on pages, indicating "go back to home" or "go back" to some other location on a web. Due to the web's porous quality, these arrows might make no sense for users encountering them. In general, Back or Forward arrows in hypertext don't make much sense. Linear relationships among pages is rare. Instead of arrows and the word back, cues on pages should indicate the destinations to which they refer.
- Check for context cues. Some designers create pages with no context cues at all. These pages are simple "slabs" of text, perhaps without even any links to cue the users as to how the page's information fits into a large system of information or knowledge.
- Check graphical/symbolic meanings. If the web uses graphics or icons, an analyst should consider whether the symbols or icons used are standard or can be misinterpreted by members of other cultures or even by the users.
Implementation Analysis
Besides analyzing a web's information and design, web analysts also should take a look at a web's implementation. The HTML that comprises a web should be correct, and, to the extent possible, the links that lead out of a web should not be stale or broken. Validating that a web conforms to current HTML specifications is key to making sure that a web is usable by many different browsers.
This analysis of implementation is not content analysis. These tools can help improve the quality of the HTML code, but not the meaning of what that code conveys. Analysts should be careful not to focus entirely on the technical validation of a web. This is analogous to focusing entirely on spelling and grammar as the single most important factor in quality writing. As a result of problems in internal or external links, web analysts should inform the web implementer.
Directory, File, and URL-Naming Checks
Because you will use the URL of your web in a variety of contexts, you should check to see whether the directory structure and naming conventions used are simple, consistent, and extendible.
First, if you are analyzing a planned web, what will its URL be? In the early days of the Web, many companies' webs were "hosted" on the sites of Web presence providers. This led to situations in which URLs for a company (for example, evergreen) included a reference to their Web presence provider (for example, globalweb.com), leading to a URL such as https://www.globalweb.com/evergreen/. This URL doesn't clearly convey the ownership or brand of the web. Instead, if you are preparing a web for a company or major brand, consider getting a domain name.
Next, take a look at the planned structure of the directories on the web. Check to see whether the resulting path names make sense, are as simple as possible, and yet allow for growth in the directory tree. One common error is to place all files at a site at the highest level, leaving no room for organizing the files into a structure for easier maintainability and usability.
At the highest level, the URL identifying your server only, such as https://www.example.com/, would be the identifier you most commonly will use in advertising and promotion, particularly in non-Web media. This page therefore should load quickly and contain information to guide users efficiently to the information content of the site.
For other files at your web site, the directory structure and the file and directory names should identify the resource named by the URL. When I created a directory structure for my on-line periodical, CMC Magazine at https://johndecember.com/cmc/mag/, I collected files about editorial policies into a single directory called editorial. This led to URLs to these files, such as the following:
https://johndecember.com/cmc/mag/editorial/style.html
https://johndecember.com/cmc/mag/editorial/plan.html
https://johndecember.com/cmc/mag/editorial/identity.html
These URLs are quite specialized, so I wouldn't expect to list them in a print advertisement. Therefore, their length is not as important as the meaning they convey. The benefit of the directory structure is that the URL can be read as a phrase. The URL https://johndecember.com/cmc/mag/editorial/plan.html, for example, is for the CMC Magazine editorial plan.
Avoid redundancy in directory or file naming. For example, the URL to the home page of the following site doesn't need to be so complicated:
https://www.example.com/html/home/examplehome.html
There's often little reason to create a directory for files of a special format (html), to use names like home, or to repeat the site name in a URL. A cleaner solution is https://www.example.com/index.html as the home page of the site. The file index.html is treated as the default page by most Web server software, so you even can leave off the index.html when providing publicity about your site.
Avoid mixed case in your directory names. A convention that provides directory names in initial uppercase and file names in all lowercase letters is a good one, but more often than not, it can lead to confusion. For example,
https://www.example.com/Projects/STAR/Docs/index.html
conveys a good structure for the documents of the STAR project, but its mix of upper- and lowercase might make it cumbersome to reference elsewhere. The mix of upper- and lowercase does convey meaning, but it is a redundant meaning when encoded into a URL; clearly, Projects is a directory because it has a subdirectory and index.html is a file because it is in the last position of the URL. The STAR project is clearly an acronym. The URL
https://www.example.com/projects/star/docs/index.html
enables the user to concentrate on the logical organization of the files on the server rather than the syntax of this organization.
Look for ways to make the directory structure of your site meaningful and stable, but as simple and extendible as possible.
HTML Validation (Internal Links)
The first step in implementation is to check to make sure that the HTML implementing the web is correct. See The HTML Toolbox.
Link Validation (Internal and External Links)
Another aspect of checking a web's links is to examine the links out of a document. This requires network information retrieval to verify that these external links are not stale or broken. Several services are available in this area.
Questions Every Web Analyst Should Ask About a Web
The sections in this article so far in this have approached web analysis from a very formal set of checklist items intended to exhaustively analyze the integrity of any web. In looking at many web sites, I've also come up with an informal list for a web critique. These questions approach some of the most common problems I often see. In special cases, there might be a very good reason why a web designer or implementer has used a technique or effect mentioned here, so all these questions should be taken in the spirit that they might have a reasonable affirmative answer--but that answer had better be good.
Wrap-Up
A web analyst examines a web's information, design, and implementation to determine its overall communication effectiveness. This process of analysis involves gathering information about the web's elements and performance and evaluating this information to see whether the web's purpose for its intended audience is being met. This analysis process involves the following:-
Information analysis to evaluate whether the web meets these checkpoints:
- Checkpoint A Attempts to reach an audience that has and will use Web access
- Checkpoint B Contributes new information (accomplishes goals that haven't already been met)
- Checkpoint C Is self-consistent (its purpose matches its objectives and specifications)
- Checkpoint D Is correct (the domain information that it presents is accurate, up to date, and complete)
- Checkpoint E Is accessed in a balanced manner, both in terms of its own files and in terms of outside links into it
- Checkpoint F Is accomplishing objectives that meet the needs of the users
- Design analysis to evaluate a web's performance, aesthetics, and usability
- Implementation analysis to verify the internal and external links for integrity and availability